Wenn du dich für japanische KI-Stimmen interessierst, kommst du an VoiceVox kaum vorbei. Die Software hat in den letzten Jahren eine ganze Subkultur geprägt: Auf YouTube, in Doujin-Spielen und auf Twitch sprechen synthetische Charaktere wie ずんだもん oder 四国めたん, als wären sie echte Personen. VoiceVox ist ein Open-Source-Sprachsynthesizer für Japanisch, kostenlos, offline lauffähig und mit einer erstaunlich lebendigen Community dahinter.
Auch wer Japanisch lernt, kann mit VoiceVox viel anfangen: Du kannst Aussprache hören, Intonation vergleichen und lange Texte in gesprochene Sprache verwandeln, ohne ein Abo oder Cloud-Dienst zu buchen. In diesem Artikel schauen wir uns an, was VoiceVox technisch ist, woher es kommt, wie es funktioniert und welche Rolle es im Ökosystem der japanischen TTS-Welt spielt.

Inhalt 11
Was ist VoiceVox?
VoiceVox ist eine Open-Source-Text-to-Speech-Software (TTS) für die japanische Sprache, entwickelt von Hiroshiba Kazuyuki. Der Quellcode der Engine liegt auf GitHub unter VOICEVOX/voicevox und steht unter der MIT-Lizenz. Du kannst die Software also ohne Lizenzgebühren herunterladen, nutzen, anpassen und in eigene Projekte einbauen.
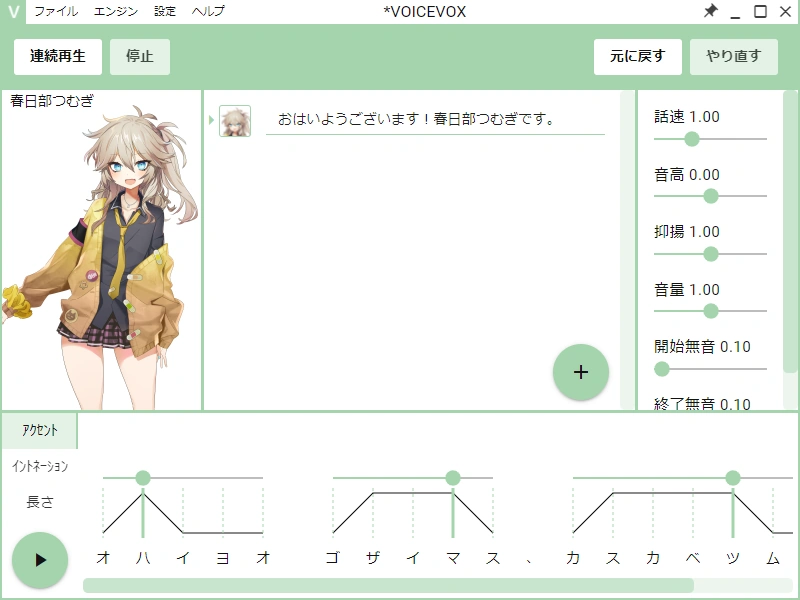
Im Kern besteht VoiceVox aus zwei Teilen: einer Engine, die Text in Audiodateien umwandelt, und einer Grafischen Oberfläche (GUI), mit der du Stimmen auswählen, Intonation anpassen und das Ergebnis als WAV exportieren kannst. Die Engine lässt sich außerdem über eine HTTP-API ansprechen, weshalb sie sich gut in andere Programme integrieren lässt, etwa in Videobearbeitung, Spiele-Engines oder Chatbots.
VoiceVox läuft offline auf Windows, macOS und Linux. Für Echtzeit-Synthese wird eine GPU mit CUDA- oder Metal-Unterstützung empfohlen, ein CPU-Modus für schwächere Hardware ist aber ebenfalls vorhanden. Damit unterscheidet sich VoiceVox deutlich von cloudbasierten Diensten wie Google Text-to-Speech oder Amazon Polly: Deine Daten verlassen den eigenen Rechner nicht.
Charaktere und Speakers
Ein zentrales Konzept in VoiceVox sind die Speaker (Sprecher). Jeder Speaker ist ein eigener Charakter mit eigener Persönlichkeit und meist mehreren Stimmvarianten. Die offizielle Distribution bringt eine ganze Reihe davon mit, zum Beispiel:
- 四国めたん (Shikoku Metan) - freundliche, jugendliche Stimme mit vielen Stilrichtungen.
- ずんだもん (Zundamon) - die wohl bekannteste Stimme, energiegeladen und in unzähligen Meme-Videos zu hören.
- 春日部つむぎ (Kasukabe Tsumugi) - sanfter, weicher Klang.
- 雨晴はう (Amehare Hau) - ruhige Erzählerin.
- 波音リツ (Namine Ritsu) - neutrale, journalistische Stimme.
- 玄野武宏 (Kurono Takehiro) - tiefer, erwachsener Ton.
- 青山龍星 (Aoyama Ryusei) und 白上虎太郎 (Shirakami Kotarou) - weitere Charakterstimmen aus dem offiziellen Set.
Zusätzlich gibt es mit Lucy eine englische Stimme, allerdings nur in eingeschränktem Umfang. VoiceVox bleibt im Kern eine Engine für Japanisch.
Geschichte und Entwicklung der japanischen TTS
Die Geschichte der japanischen Sprachsynthese beginnt lange vor VoiceVox. Bereits in den 2000er-Jahren brachte das Unternehmen AH-Software mit VOICEROID eine kommerzielle TTS-Reihe auf den Markt, die vor allem in Doujin- und Anime-Kreisen genutzt wurde. Diese Stimmen galten lange als Standard, waren aber an Lizenzgebühren gebunden.
Mit dem Aufkommen leistungsfähiger Deep-Learning-Modelle ab etwa 2020 veränderte sich die Szene grundlegend. Hiroshiba Kazuyuki, der zuvor bereits Erfahrungen mit neuronaler Sprachsynthese gesammelt hatte, begann 2020/2021 mit der Entwicklung von VoiceVox. Im Sommer 2021 wurde die erste Version als Open Source auf GitHub veröffentlicht. Die Idee dahinter: Eine moderne, KI-basierte Alternative zu VOICEROID zu schaffen, die frei verfügbar ist.
Der Erfolg kam schnell. Innerhalb weniger Monate wuchs die Community auf Discord, Twitter und GitHub stark an. Immer mehr unabhängige Sprecher und Studios stellten eigene Stimmen zur Verfügung, die offiziell in VoiceVox eingebunden werden konnten. Die Integration mit A.I.VOICE (dem Nachfolger von VOICEROID) schuf zudem eine Brücke zwischen kommerzieller und freier TTS-Welt.
Die Technik hinter VoiceVox
Technisch gesehen ist VoiceVox eine neuronale Text-to-Speech-Engine. Das bedeutet, dass die Sprachsynthese nicht mehr aus aufgenommenen Silben zusammengesetzt wird, sondern ein trainiertes KI-Modell aus Text ein komplettes Audiosignal erzeugt.
Modelle und Pipeline
Die Architektur folgt dem klassischen zweistufigen Aufbau moderner TTS-Systeme:
- Ein akustisches Modell erzeugt aus dem Eingabetext ein Mel-Spektrogramm, also eine Art Frequenzkarte über die Zeit.
- Ein Vokoder wandelt dieses Spektrogramm in eine hörbare Wellenform (WAV) um.
Als Frameworks kommen typischerweise PyTorch und vortrainierte Modelle wie Style-Bert-VITS2 oder ähnliche Architekturen zum Einsatz, die über Plattformen wie Hugging Face verteilt werden. Die genauen Modelle pro Speaker werden vom VoiceVox-Team kuratiert und in regelmäßigen Updates ausgetauscht, wenn bessere Versionen verfügbar sind.
Hardware und API
Für die Echtzeit-Synthese empfiehlt sich eine moderne GPU, da die neuronalen Modelle sonst zu langsam laufen. VoiceVox unterstützt NVIDIA CUDA sowie Apple Metal, sodass auch Macs mit Apple Silicon die Engine effizient nutzen können. Wer keine passende GPU besitzt, kann auf den CPU-Modus zurückgreifen, der allerdings deutlich langsamer arbeitet.
Für die Integration in andere Software bietet VoiceVox eine HTTP-API. Über Endpunkte wie /audio_query und /synthesis können Programme Text an die Engine schicken und Audio zurückbekommen. Das macht VoiceVox zu einer beliebten Backend-Lösung für VOICEVOX Talk, Discord-Bots, OBS-Plugins und Indie-Games.
Eigenes Stimmentraining
Wer eigene Stimmen trainieren möchte, kann dies mit den passenden Open-Source-Werkzeugen tun. Voraussetzung sind in der Regel mehrere Stunden sauberes Audiomaterial der gewünschten Stimme. Solche selbst trainierten Modelle lassen sich anschließend als zusätzliche Speaker in die Engine einbinden, was die Anpassungsmöglichkeiten enorm erweitert.
Verwendungszwecke und Anwendungsfälle
Die Einsatzbereiche von VoiceVox sind breit gefächert. Einige der häufigsten Szenarien:
- YouTube und Videoerstellung: Erklärvideos, Anime- und Spielerezensionen, Erklärfilme. Die einfache Bedienung und die unterhaltsamen Charakterstimmen senken die Hürde für eigene Produktionen.
- VTuber und Live-Streaming: Viele VTuber nutzen VoiceVox als Chat- oder Kommentarstimme, besonders bei kleineren Streams oder für Nebencharaktere.
- Doujin-Spieleentwicklung: Indie-Studios ohne professionelles Voice-Casting können Dialoge in spielbarer Qualität produzieren.
- Anime-Fan-Synchronisationen: Doujin-Projekte, die ursprünglich nur als stumme Doujinshi existierten, bekommen mit VoiceVox eine vertonte Version.
- Bildung und Sprachenlernen: Wer Japanisch lernt, kann sich eigene Beispielsätze vorlesen lassen und Aussprache üben.
- Hörbücher und Podcasts: Automatisch generierte Audioinhalte für längere Texte.
- Voice-Chat-Bots: Discord-Bots, die mit echten Sprachantworten statt nur Text antworten.
- Zugänglichkeit: Vorlese-Tools für sehbehinderte Nutzer oder für Texte, die lieber gehört als gelesen werden.
Verfügbare Stimmen und Lizenzen
Das Stimmenangebot wächst mit jedem Update. Die Zahl der offiziellen Speaker liegt mittlerweile im niedrigen zweistelligen Bereich, dazu kommen zahlreiche Community-Speaker, die unter eigenen Lizenzen verbreitet werden.
Lizenzmodelle
Die Lizenzlage ist differenziert. Die VoiceVox Engine selbst steht unter der MIT-Lizenz und darf auch kommerziell genutzt werden. Die Stimmmodelle hingegen haben jeweils eigene Lizenzen, die von den Sprechern oder Studios festgelegt werden. Manche sind frei, andere erlauben nur nicht-kommerzielle Nutzung, und für kommerzielle Projekte ist teilweise ein AudioMerge mit dem Originalsprecher erforderlich.
Bevor du eine Stimme in einem kommerziellen Projekt einsetzt, solltest du daher immer die jeweiligen Lizenzbedingungen prüfen. Die VoiceVox-Dokumentation verlinkt die Bedingungen direkt in der Stimmenauswahl.
VoiceVox und die Zukunft der japanischen TTS
VoiceVox steht nicht allein da. Im kommerziellen Bereich konkurrieren VOICEROID, A.I.VOICE und VOICEPEAK mit eigenen Stimmen, im Open-Source-Bereich gibt es Projekte wie COEIROINK und LMROID. Was VoiceVox besonders macht, ist die Kombination aus offener Lizenz, einfacher Bedienung und einer aktiven Community, die ständig neue Inhalte produziert.
Die offene Architektur bringt allerdings auch Grenzen mit sich: Andere Sprachen als Japanisch werden nur rudimentär unterstützt, und die Qualität hängt stark vom jeweiligen Speaker-Modell ab. In den kommenden Jahren ist zu erwarten, dass neuere KI-Ansätze wie neuronale Codec-Sprache (etwa VALL-E oder SoundStorm) auch in der japanischen TTS-Szene Einzug halten.
Themen wie Voice-Cloning und Deepfakes werden die Community weiter beschäftigen, da sie sowohl kreative Chancen als auch ethische Fragen mit sich bringen. Hier sind klare Regeln zur Einwilligung und Nutzung entscheidend, damit offene TTS nicht in Misskredit gerät.
VoiceVox ist heute ein zentraler Baustein der japanischen KI-Sprachszene, eine Art offene Alternative zu kommerziellen Engines, getragen von einer lebendigen Community. Wer verstehen will, wie moderne japanische TTS funktioniert, kommt an diesem Projekt kaum vorbei. Und wer selbst Audio produziert, hat damit ein Werkzeug an der Hand, das vor wenigen Jahren noch nicht öffentlich verfügbar war.






Community
Kommentare
0 Kommentare
In dieser Sprache gibt es noch keine veröffentlichten Kommentare.
Kommentar senden