Se você anda circulando por YouTube japonês, jogos doujin ou lives de VTubers, é bem provável que já tenha ouvido o VoiceVox sem perceber de onde vinha aquela voz. O software moldou aos poucos uma pequena subcultura: personagens sintéticos como ずんだもん (Zundamon) e 四国めたん (Shikoku Metan) leem roteiros, apresentam vídeos e respondem perguntas com uma naturalidade que engana quem chega desprevenido. VoiceVox é um motor de texto para voz de código aberto focado em japonês, gratuito, capaz de rodar totalmente offline e sustentado por uma comunidade bem ativa de desenvolvedores, ilustradores e criadores de conteúdo.
Ele também vira uma ferramenta útil para quem estuda japonês: dá para ouvir como uma frase deve soar, comparar a entonação entre diferentes falantes e transformar trechos longos de texto em áudio para ouvir no caminho do trabalho ou entre uma tarefa e outra. Neste artigo, vamos passar pelo que o VoiceVox é de fato, de onde veio, como a tecnologia funciona por dentro, quais vozes e licenças acompanham o pacote e qual é o papel dele no ecossistema mais amplo de síntese de fala com IA no Japão.

Sumário 7
O que é o VoiceVox?
VoiceVox é um aplicativo de texto para voz (TTS) de código aberto pensado para o idioma japonês, desenvolvido por Hiroshiba Kazuyuki. O código-fonte do motor fica no GitHub, no repositório VOICEVOX/voicevox, e é distribuído sob a Licença MIT, o que significa que qualquer pessoa pode baixar, executar, modificar e embutir o motor em outros projetos sem pagar royalties.
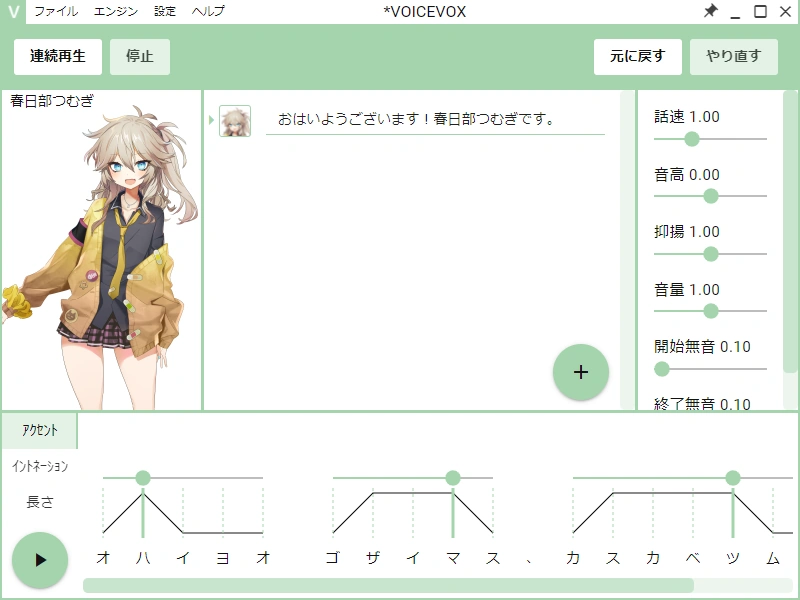
Na prática, o VoiceVox se divide em duas partes. Um motor de texto para voz, que transforma o japonês escrito em áudio, e uma interface gráfica (GUI) que funciona como um editor leve: você digita o texto, escolhe o personagem, ajusta entonação, velocidade, pausas e volume, e exporta o resultado em WAV. O motor também roda de forma independente como um servidor local com uma API HTTP, o que permite integrá-lo em pipelines de produção, plugins de edição de vídeo, bots de chat ou ferramentas de legendagem automática.
Para os padrões japoneses de TTS, o VoiceVox traz algumas decisões de produto marcantes. Primeiro, ele é gratuito tanto para uso comercial quanto para uso pessoal, em um mercado onde alternativas como VOICEROID, A.I.VOICE e VOICEPEAK costumam cobrar licenças individuais por voz. Segundo, ele funciona totalmente offline: o motor roda localmente, e nenhum áudio precisa passar por um servidor externo para ser gerado. Por fim, os personagens não são meros avatares: cada um representa um conjunto de estilos de voz (sussurrado, animado, calmo, sério, neutro) gravados com consentimento e modelos de IA treinados sobre essas amostras.
Para quem o VoiceVox faz sentido
No dia a dia, o público do VoiceVox se divide em três grandes grupos. O primeiro é o de criadores de conteúdo: YouTubers que precisam narrar vídeos sem se expor com a própria voz, streamers de VTuber que querem respostas rápidas em live, desenvolvedores de jogos indie que precisam de dublagem sem contratar atores. O segundo é o de estudantes e professores de japonês, que usam o motor para ouvir pronúncia, comparar variações de pitch e gerar materiais de áudio. O terceiro é o de desenvolvedores e pesquisadores, que se interessam pelo motor em si, pelos modelos acústicos distribuídos e pela possibilidade de treinar vozes próprias.
História e desenvolvimento da TTS japonesa
Para entender o VoiceVox, vale olhar antes para o cenário de síntese de voz no Japão, que tem uma história própria, anterior à onda recente de IA generativa. O mercado japonês de TTS comercial começou a ganhar forma nos anos 2000 com produtos como VOICEROID, lançado pela AH-Software em 2007. VOICEROID trazia personagens como Kotonoha Akane e Kotonoha Aoi e rapidamente se tornou referência em vídeos doニコニコ動画 (Niconico), o portal de vídeos que foi, por muito tempo, o principal celeiro de cultura otaku e de experimentos criativos com voz sintética no Japão.
Esse ecossistema tinha duas características marcantes. A primeira era o foco em vozes-personagem: cada produto comercial era vendido com um elenco fixo de personagens, e o modelo de licenciamento se parecia mais com o de voicebanks para歌声合成 (síntese de canto, como Vocaloid e UTAU) do que com o de software tradicional. A segunda era a forte ligação com a comunidade: ilustradores criavam visuais, fãs escreviam roteiros, e os personagens ganhavam vida própria em vídeos amadores muito antes de qualquer empresa pensar em marketing oficial.
Foi nesse contexto que Hiroshiba Kazuyuki, conhecido pelo nickname Hiroshiba, começou a trabalhar no VoiceVox por volta de 2020, com o código-fonte sendo aberto no GitHub em 2021. A proposta era simples e, ao mesmo tempo, ousada: oferecer um motor de TTS neural com qualidade próxima à de produtos comerciais pagos, mas gratuito, aberto e sem amarras de licenciamento por personagem. A primeira reação da comunidade foi cética, porque合成 de voz neural de alta qualidade costuma exigir grandes volumes de dados e poder de processamento, mas o resultado veio surpreendendo pela naturalidade em japonês, mesmo em hardware doméstico.
Em pouco tempo, o VoiceVox ganhou tração por meio de integrações com a plataforma A.I.VOICE, ferramentas de legendagem automática, plugins para editores como AviUtl, e uma leva de novos personagens contribuídos por ilustradores e estúdios. A combinação de API HTTP, documentação clara e a cultura de contribuição aberta fizeram com que desenvolvedores individuais criassem bibliotecas em Python, wrappers em JavaScript e integrações com OBS Studio e Discord, ampliando o uso bem além do nicho original.
A tecnologia por trás do VoiceVox
Por trás da interface amigável, o VoiceVox é um pipeline clássico de TTS neural moderno, organizado em três blocos principais. O primeiro é o front-end de texto, que recebe o japonês escrito (uma mistura de hiragana, katakana, kanji e pontuação) e faz a normalização: converte numerais em leituras, resolve formas variantes de kanji, atribui pitch accent aos compostos e marca pausas e ênfases.
O segundo bloco é o modelo acústico, que recebe essa sequência de fonemas anotada e gera um mel-espectrograma, isto é, uma representação visual de como o sinal de fala evolui no tempo. O VoiceVox é frequentemente associado a arquiteturas como Style-Bert-VITS2 e GPT-SoVITS, modelos baseados em Transformer e em mecanismos de atenção que aprenderam a variar o estilo da voz a partir de pequenas amostras de referência. Cada personagem do VoiceVox traz um ou mais modelos acústicos treinados sobre horas de gravações, e o resultado é a possibilidade de alternar entre entoações sem retreinar nada a cada uso.
O terceiro bloco é o vocoder, que converte o mel-espectrograma em forma de onda de áudio propriamente dita. O motor traz opções que equilibram qualidade e velocidade, e aceita aceleração por GPU quando o hardware oferece suporte, seja via CUDA em placas NVIDIA, seja via Metal em Macs Apple Silicon. Em máquinas mais modestas, o modo CPU continua funcional, embora gere áudio mais devagar. Para projetos maiores, dá para distribuir a carga entre várias instâncias do motor, cada uma servindo um personagem diferente.
Para integração com outros softwares, o VoiceVox expõe uma API HTTP local que aceita texto, devolve áudio em WAV e permite consultar a lista de vozes disponíveis. É essa API que habilita o ecossistema de plugins, bots de Discord, ferramentas de legendagem automática e geradores de vídeo curto. Existe também um motor secundário para ajuste fino: com material de áudio suficiente, é possível treinar um modelo de voz próprio a partir das ferramentas distribuídas pelo projeto, o que abriu espaço para experimentos amadores e projetos de pesquisa em universidades japonesas.
Casos de uso e aplicações
O leque de aplicações práticas do VoiceVox é amplo e continua crescendo. No YouTube japonês, é comum encontrar vídeos explicativos, ensaios, resenhas de anime e até material didógico narrado por uma voz sintética, com legendas automáticas ou semi-automáticas geradas em cima do áudio. A escolha costuma combinar bem com a estética visual minimalista, e o resultado tende a soar consistente entre episódios.
No universo VTuber, o VoiceVox virou uma peça quase obrigatória para quem quer operar um personagem 2D ou 3D sem depender de um ator de voz em tempo integral. Em lives no YouTube e no Twitch, respostas prontas, saudações de abertura, avisos de pausa e interação com o chat podem ser sintetizadas a partir de scripts, mantendo o personagem ativo mesmo quando o responsável humano precisa se ausentar. Em canais de reação, é frequente que comentários longos sejam lidos pelo motor enquanto o VTuber mantém a câmera ligada.
Em jogos doujin, o VoiceVox reduziu drasticamente o custo de produção de dublagem. Títulos produzidos por equipes pequenas, ou até por uma pessoa só, conseguem oferecer diálogos completos em japonês, com variedade de personagens e entonação consistente, sem a necessidade de contratar estúdio ou atores profissionais. Isso mudou a relação de costo-benefício da produção de visual novels, jogos de horror, RPGs curtos e simulações narrativas, que ganharam um novo fôlego no mercado independente.
Para quem está aprendendo japonês, o motor permite ouvir como uma frase deve soar, ouvir a mesma frase em vozes diferentes para captar variações de pitch accent, e gerar audiolivros personalizados a partir de textos em japonês. Em acessibilidade, leitores de tela e ferramentas de apoio a pessoas com deficiência visual passaram a usar o VoiceVox em conjunto com sintetizadores tradicionais para oferecer vozes mais expressivas em conteúdo em japonês. Em podcasts, há ainda um uso crescente de geração automática de vinhetas, chamadas e segmentos de recapitulação.
Vozes disponíveis e licenças
O elenco oficial do VoiceVox é extenso e cresce a cada atualização. Cada personagem é acompanhado por um conjunto de estilos de voz, que podem variar entre fala normal, sussurro, voz animada, voz séria, grito e modalidades intermediárias. Entre os personagens mais usados estão 四国めたん (Shikoku Metan), ずんだもん (Zundamon), 春日部つむぎ (Kasukabe Tsumugi), 雨晴はう (Amehare Hau), 波音リツ (Namine Ritsu), 玄野武宏 (Kurono Takehiro) e 白上虎太郎 (Shirakami Kotarou), entre outros, alguns deles com mais de uma dezena de estilos de voz cadastrados. A 青山龍星 (Aoyama Ryusei) também faz parte do pacote em lançamentos mais recentes.
Para falantes de outras línguas, existe um número bem menor de vozes: o projeto tem experimentado suporte limitado a inglês por meio do personagem Lucy, mas o grosso do elenco continua otimizado para japonês. Como o motor é focado nesse idioma, vozes treinadas em outros idiomas tendem a soar artificiais ou a exigir modelos próprios.
No campo das licenças, é importante separar dois blocos. O VoiceVox Engine, isto é, o software em si, é distribuído sob Licença MIT, que permite uso comercial, modificação e redistribuição, desde que mantidos os avisos de copyright. As vozes, por outro lado, seguem licenças definidas por personagem: cada voz traz termos próprios, definidos pelo autor ou estúdio que cedeu as gravações, e é obrigatório consultar a licença específica antes de uso comercial. A página oficial do projeto mantém a lista atualizada de vozes, suas licenças e os requisitos de atribuição.
Para projetos maiores, ainda existe o VOICEVOX AudioMerge, um utilitário que facilita combinar áudios gerados pelo motor em um único arquivo final, útil para podcasts, vídeos longos e material de estudo. O utilitário segue a licença do motor principal e é uma mão na roda para quem gera muito conteúdo em lote.
VoiceVox e o futuro da TTS japonesa
Comparado a produtos comerciais como VOICEROID, A.I.VOICE e VOICEPEAK, o VoiceVox se posiciona como a alternativa de código aberto: gratuito, transparente, extensível e construído em cima de contribuições da comunidade. Em troca, exige um pouco mais de conhecimento técnico do usuário, especialmente para quem quer tirar proveito da API, treinar vozes próprias ou automatizar pipelines. Para quem busca uma experiência mais plug-and-play, as alternativas comerciais continuam relevantes; para quem quer mexer no motor e adaptá-lo a projetos próprios, o VoiceVox é o ponto de partida natural.
Em termos de limitações, vale destacar três pontos. O primeiro é o foco no japonês: o motor é excelente nesse idioma, mas o suporte a outras línguas ainda é restrito. O segundo é a exigência de hardware razoável para geração em tempo real, especialmente com áudios longos. O terceiro é a curva de aprendizado para configurar integrações com editores de vídeo, OBS e outras ferramentas, embora a comunidade tenha publicado bastante material em japonês para reduzir essa barreira.
Olhando para frente, a área de TTS japonesa atravessa um momento de transição. Modelos generativos baseados em grandes arquiteturas de linguagem, codecs neurais como VALL-E e SoundStorm, e técnicas de clonagem de voz com poucas amostras estão redefinindo o que é possível. O VoiceVox continua relevante justamente porque democratiza o acesso a essas técnicas, dá aos usuários a possibilidade de treinar vozes próprias e mantém um motor aberto, com código disponível para auditoria e adaptação.
Esse cenário também traz debates éticos relevantes. A mesma tecnologia que permite dublar um jogo doujin com uma voz original abre espaço para clonagem não autorizada, deepfakes e uso indevido de vozes reais. O VoiceVox trabalha com gravações cedidas com consentimento e mantém licenças claras por personagem, mas o ecossistema mais amplo de TTS precisará continuar avançando em regulação, divulgação responsável e mecanismos de proteção, à medida que a qualidade da síntese se aproxima cada vez mais da voz humana.
Para acompanhar o projeto, vale seguir os canais oficiais no GitHub, no site do desenvolvedor, e nas comunidades em Discord e Twitter/X, onde costumam ser anunciadas novas vozes, atualizações do motor e experimentos da comunidade. Se você trabalha com conteúdo em japonês, produz material didático ou simplesmente tem curiosidade por合成 de voz, o VoiceVox é um daqueles projetos que vale a pena instalar e testar por conta própria, mesmo que seja só para ouvir a mesma frase lida em dez vozes diferentes.







Comunidade
Comentários
0 comentários
Ainda não há comentários publicados neste idioma.
Enviar um comentário