Se hai trascorso un po' di tempo su YouTube giapponese, tra giochi doujin o nelle dirette di qualche VTuber, è molto probabile che tu abbia già sentito VoiceVox anche senza riconoscerne il nome. Il software ha modellato una piccola subcultura: personaggi sintetici come ずんだもん (Zundamon) e 四国めたん (Shikoku Metan) leggono copioni, conducono video e rispondono a domande con voci che sembrano sorprendentemente vive. VoiceVox è un motore di sintesi vocale open source pensato per il giapponese, gratuito, in grado di funzionare completamente offline e sostenuto da una comunità insolitamente attiva di sviluppatori, illustratori e creatori di contenuti.
È anche uno strumento pratico per chi studia la lingua: con VoiceVox puoi ascoltare come dovrebbe suonare una frase, confrontare l'intonazione tra diversi parlanti e trasformare passaggi lunghi di giapponese in audio da riascoltare in metro, in casa o tra un impegno e l'altro. In questo articolo vediamo che cos'è VoiceVox, da dove arriva, come funziona la tecnologia al suo interno, quali voci e licenze include e quale ruolo occupa nell'ecosistema più ampio della sintesi vocale giapponese con IA.

Indice 15
Cos'è VoiceVox
VoiceVox è un'applicazione di sintesi vocale (TTS) open source pensata per la lingua giapponese, sviluppata da Hiroshiba Kazuyuki. Il codice sorgente del motore è ospitato su GitHub all'indirizzo VOICEVOX/voicevox ed è distribuito con licenza MIT: questo significa che è possibile scaricarlo, eseguirlo, modificarlo e integrarlo in altri progetti senza pagare royalty.
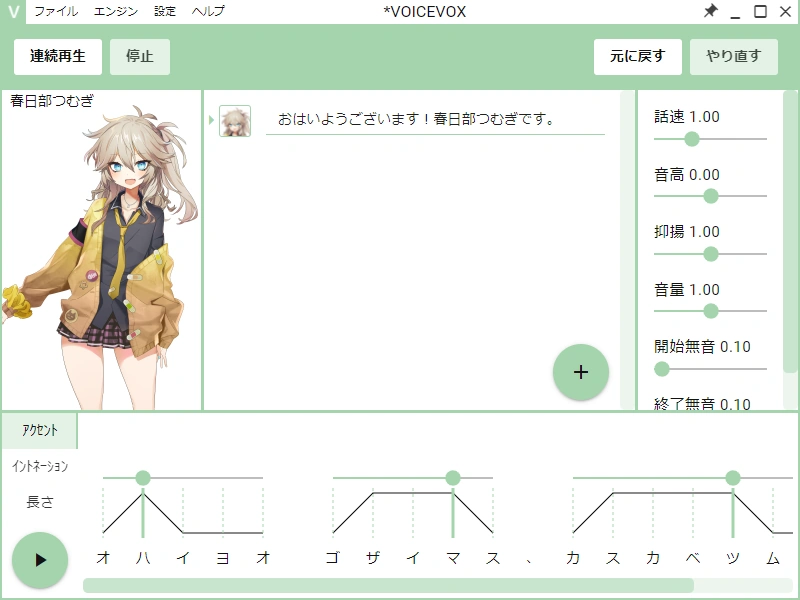
In pratica VoiceVox è diviso in due componenti. Un motore di sintesi vocale che trasforma testo giapponese in audio, e un'interfaccia grafica che permette di scegliere la voce, regolare intonazione e velocità, aggiungere pause, esportare in WAV e gestire dizionari personalizzati. Il motore è inoltre esposto tramite un'API HTTP, il che lo rende facile da integrare in software di terze parti: editor video, sistemi di sottotitolazione, OBS, bot e pipeline di generazione contenuti.
Il software gira su Windows, macOS e Linux, funziona offline una volta installato e supporta sia l'accelerazione GPU (CUDA su NVIDIA, Metal su Apple Silicon) sia una modalità CPU più lenta ma utilizzabile su hardware meno recente. Per chi vuole sperimentare senza installare nulla, esiste anche una versione browser che gira direttamente nel client, utile per prove rapide o per chi usa Chromebook o tablet.
Chi c'è dietro VoiceVox
Il progetto nasce da Hiroshiba Kazuyuki, sviluppatore giapponese già noto in passato per lavori su algoritmi di sintesi vocale. Il primo rilascio pubblico risale al 2020, con un'evoluzione molto rapida nei due anni successivi: voci sempre più naturali, un editor integrato, il supporto ad API e un passaggio graduale a modelli di rete neurale di nuova generazione. Intorno al progetto si è formata in fretta una comunità che contribuisce con dizionari, termini tecnici, integrazioni e nuove voci.
Storia e sviluppo della TTS giapponese
Per capire VoiceVox conviene fare un passo indietro. La sintesi vocale giapponese ha una storia più lunga di quanto si pensi: i primi software commerciali dedicati risalgono agli anni duemila, con prodotti come VOICEROID di AH-Software, che a partire dal 2007 hanno portato sul mercato voci sintetiche leggibili e utilizzabili in produzione audio, soprattutto nell'ambito dei video amatoriali e del doujin.
La differenza con VoiceVox è soprattutto di filosofia. VOICEROID e i suoi successori (A.I.VOICE, VOICEPEAK) sono software proprietari, con voci acquistabili singolarmente e licenze che regolano l'uso commerciale. VoiceVox parte da un approccio opposto: il motore è aperto, le voci ufficiali sono gratuite per l'uso non commerciale, e la comunità può proporre estensioni, dizionari e integrazioni. Una parte delle voci è rilasciata con termini più permissivi grazie ad accordi specifici con i doppiatori e le software house, e va verificata di volta in volta prima di un uso commerciale.
Lo sviluppo di VoiceVox si è intrecciato con la diffusione di modelli di sintesi neurale open, come Style-Bert-VITS2 e GPT-SoVITS, che hanno reso possibile allenare voci giapponesi di buona qualità partendo da dataset relativamente ridotti. I modelli delle voci di VoiceVox sono distribuiti anche su Hugging Face, con licenze specifiche per ciascun parlante, e possono essere scaricati e usati indipendentemente dall'interfaccia grafica.
La tecnologia dietro VoiceVox
Una pipeline TTS giapponese è più articolata di quanto sembri, e VoiceVox la rende accessibile. Il testo in ingresso passa attraverso uno strato testuale che gestisce la normalizzazione: numeri, simboli, acronimi, letture alternative, kun'yomi e on'yomi. È qui che entrano in gioco i dizionari, compresi quelli generati dalla comunità, che permettono di correggere letture sbagliate o ambigue.
Una volta normalizzato, il testo viene trasformato in una sequenza di fonemi con accenti, pause e caratteristiche prosodiche. A questo punto entra in gioco il modello acustico, che produce un mel-spettrogramma, ovvero una rappresentazione intermedia del suono. Il vocoder converte infine lo spettrogramma in una forma d'onda vera e propria a frequenza di campionamento audio.
Accelerazione GPU e CPU
La fase più pesante è la sintesi acustica e la decodifica del vocoder. Su macchine con GPU NVIDIA recente, VoiceVox sfrutta CUDA per generare audio anche in tempo reale su testi lunghi. Sui Mac con processore Apple Silicon, viene usato Metal, con un netto miglioramento rispetto alla sola CPU. Chi lavora su portatili meno recenti o su macchine senza GPU dedicata può comunque usare VoiceVox in modalità CPU: la generazione è più lenta, ma resta utilizzabile per produzioni di pochi minuti.
API e integrazioni
Uno dei punti di forza del progetto è l'API HTTP del motore. Una volta avviato, VoiceVox Engine espone endpoint per la sintesi, la lista delle voci, la regolazione dei parametri e la generazione di audio in vari formati. Questo ha permesso la nascita di un ecosistema di plugin, tool e wrapper: estensioni per OBS, plugin per editor come AviUtl, integrazioni con software di sottotitolazione, bot Discord, strumenti di lettura assistita e persino progetti di lettura automatica di codice.
Casi d'uso e applicazioni
VoiceVox è nato come strumento per chi crea contenuti, e i suoi casi d'uso lo dimostrano.
YouTube e contenuti vocali
Su YouTube giapponese, VoiceVox è usato in canali di spiegazione, recensioni di anime, video educativi e let’s play. L'uso più caratteristico è la voce di Zundamon, che è diventata una specie di mascotte: copioni scritti, voce sintetica, montaggio leggero. È un formato che ha aperto la produzione audio a chi non ha un microfono di qualità o non si sente a proprio agio a usare la propria voce.
VTuber e dirette
Nell'ambito dei VTuber e delle live, VoiceVox viene usato in due modi: come voce di personaggi sintetici veri e propri, oppure come supporto per doppiare in giapponese dirette in cui l'autore preferisce mantenere l'anonimato vocale. L'integrazione con OBS e con i principali software di streaming è ormai una prassi consolidata.
Giochi doujin e fanwork
Nei giochi doujin, in particolare nelle produzioni di visual novel e avventure, VoiceVox permette di doppiare i personaggi senza ricorrere a doppiatori professionisti. È un cambiamento piccolo ma importante: sviluppatori indipendenti possono costruire scene con dialoghi parlati, anche se il budget è quello di una produzione amatoriale.
Istruzione e accessibilità
Per chi studia giapponese, VoiceVox è un banco di prova immediato: permette di ascoltare una frase, confrontare diverse voci, regolare la velocità e sentire le differenze di intonazione. È anche uno strumento di accessibilità utile a chi ha difficoltà di lettura o vuole ascoltare testi lunghi senza dipendere da un servizio cloud.
Bot e assistenti vocali
Grazie all'API HTTP, VoiceVox è facile da inserire in bot Discord, assistenti vocali casalinghi e piccoli esperimenti di interazione vocale. È un terreno di sperimentazione più che un prodotto finito, ma è esattamente il tipo di uso che il progetto incoraggia.
Voci disponibili e licenze
Le voci ufficiali di VoiceVox sono il tratto più riconoscibile del progetto. Ogni parlante è associato a un personaggio con un'identità visiva curata dalla comunità, ed è declinato in più stili: la stessa voce può avere una versione normale, una sussurrata, una più acuta, una più matura, e così via.
Tra i personaggi più noti ci sono 四国めたん (Shikoku Metan), con diverse varianti di tono, ずんだもん (Zundamon), la celebre mascotte dai modi infantili, 春日部つむぎ (Kasukabe Tsumugi), voce dal timbro più caldo, 雨晴はう (Amehare Hau), 波音リツ (Namine Ritsu), pensata per un parlato più calmo, 玄野武宏 (Kurono Takehiro), con uno stile più posato, e 白上虎太郎 (Shirakami Kotarou). La lineup cresce con ogni release: a questi si sono aggiunti, nel tempo, personaggi come 青山龍星 (Aoyama Ryusei) e varietà pensate per generi specifici.
Per chi cerca un supporto, seppur limitato, anche in inglese, esistono voci come Lucy, sebbene la qualità e la naturalezza restino lontane da quelle delle voci giapponesi. È un segnale chiaro: VoiceVox resta uno strumento nativamente giapponese, e le altre lingue sono un'area di sviluppo più che un punto di arrivo.
Licenze e uso commerciale
Sul fronte delle licenze, la situazione va letta con attenzione. Il motore è distribuito con licenza MIT, estremamente permissiva: uso commerciale consentito, modifica consentita, ridistribuzione consentita, a patto di mantenere la nota di copyright. Le voci, invece, hanno licenze variabili, spesso specifiche per ciascun personaggio: molte sono gratuite per uso personale e didattico, ma richiedono condizioni diverse per l'uso commerciale. Il tool integrato AudioMerge permette di combinare e processare clip in modo coerente, ma non sostituisce la verifica dei termini d'uso della singola voce. Prima di pubblicare un video monetizzato o un prodotto che usa una voce specifica, è buona prassi controllare la pagina della voce sul sito ufficiale di VOICEVOX.
VoiceVox e il futuro della TTS giapponese
Rispetto al software commerciale, VoiceVox ha un vantaggio evidente: trasparenza. Il codice è leggibile, i modelli sono scaricabili, le pipeline sono documentate. Questo permette a ricercatori, hobbisti e piccoli team di capire cosa succede sotto il cofano, e di intervenire in caso di bisogno. È un approccio che ricorda da vicino quello di altri progetti di IA giapponese open, e che si sposa bene con la cultura del doujin e della condivisione tecnica.
Il limite principale resta linguistico: VoiceVox è pensato per il giapponese, e le altre lingue, dove presenti, sono ancora un work in progress. Anche la formazione di voci personalizzate richiede un minimo di competenza tecnica e dataset puliti, anche se gli strumenti stanno diventando più accessibili release dopo release.
Lo sguardo sul futuro tocca almeno tre direttrici. La prima è la sintesi in tempo reale, con latenza sempre più bassa, utile per live e assistenti vocali. La seconda è l'integrazione con modelli generativi più ampi, come i codec neurali alla VALL-E o SoundStorm, che promettono clonazione e riproduzione a partire da pochi secondi di audio. La terza è l'etica: clonazione della voce, deepfake audio, consenso dei doppiatori, trasparenza nella divulgazione. Sono temi che riguardano VoiceVox come qualsiasi altro motore TTS, e che il progetto open source ha il vantaggio di poter affrontare in modo esplicito.
La comunità, intanto, continua a essere il vero motore del progetto: discord, Twitter e GitHub sono i luoghi dove si propongono nuove voci, si correggono dizionari, si sviluppano integrazioni. È una dinamica che somiglia molto a quella di altri ecosistemi giapponesi di nicchia: pochi sviluppatori centrali, molti contributori, e una cultura della cura del dettaglio che si vede nei risultati.
Se ti interessa la sintesi vocale, vale la pena tenere d'occhio VoiceVox: è un buon esempio di come un progetto open source giapponese possa ritagliarsi uno spazio reale accanto ai software commerciali, e di come la qualità tecnica e la comunità possano crescere insieme.







Community
Commenti
0 commenti
Non ci sono ancora commenti pubblicati in questa lingua.
Invia commento