일본어 유튜브, 동인 게임, VTuber 방송을 종종 들여다본다면 VoiceVox라는 이름을 모른 채로 그 목소리를 이미 여러 번 들었을 가능성이 큽니다. ずんだもん이나 四国めたん 같은 합성 캐릭터들이 대본을 읽고, 영상을 진행하고, 질문에 답하는 장면은 이미 일본어 인터넷의 한 장르가 되었습니다. VoiceVox는 일본어 전용으로 만들어진 오픈소스 텍스트 음성 변환(TTS) 엔진으로, 무료로 내려받아 오프라인에서 동작하고, 개발자와 일러스트레이터, 콘텐츠 크리에이터로 구성된 활발한 커뮤니티가 함께 자라온 프로젝트입니다.
일본어를 공부하는 사람에게도 VoiceVox는 꽤 실용적인 도구입니다. 한 문장이 어떻게 들려야 하는지 직접 들어볼 수 있고, 화자별로 운율을 비교할 수 있으며, 긴 지문을 음성 파일로 바꿔 출퇴근길이나 가사 작업 중에 돌려 들을 수 있습니다. 이 글에서는 VoiceVox가 정확히 무엇인지, 어디서 시작되었는지, 내부 기술이 어떻게 구성되어 있는지, 어떤 음성과 라이선스를 제공하는지, 그리고 일본어 음성 합성 생태계 안에서 어떤 위치를 차지하고 있는지를 한꺼번에 정리합니다.

목차 14
VoiceVox란 무엇인가
VoiceVox는 일본어에 특화된 오픈소스 텍스트 음성 합성(TTS) 애플리케이션으로, 개발자는 Hiroshiba Kazuyuki입니다. 엔진의 소스 코드는 GitHub의 VOICEVOX/voicevox 저장소에 공개되어 있으며 라이선스는 MIT입니다. 라이선스 비용 없이 내려받아 실행하고, 수정하고, 다른 프로젝트에 끼워 넣어 쓸 수 있다는 뜻입니다.
구조는 크게 두 부분으로 나뉩니다. 일본어 텍스트를 음성 데이터로 바꾸는 TTS 엔진과, 목소리 선택과 파라미터 조정을 도와주는 그래픽 사용자 인터페이스(GUI)입니다. 엔진 자체는 HTTP API로도 호출할 수 있어서 영상 편집 도구, 전자책 리더, 챗봇 같은 외부 서비스에 통합하기 좋습니다. 또한 GPU와 CPU 모드를 모두 지원하므로, 고성능 머신이 없는 환경에서도 사용할 수 있습니다.
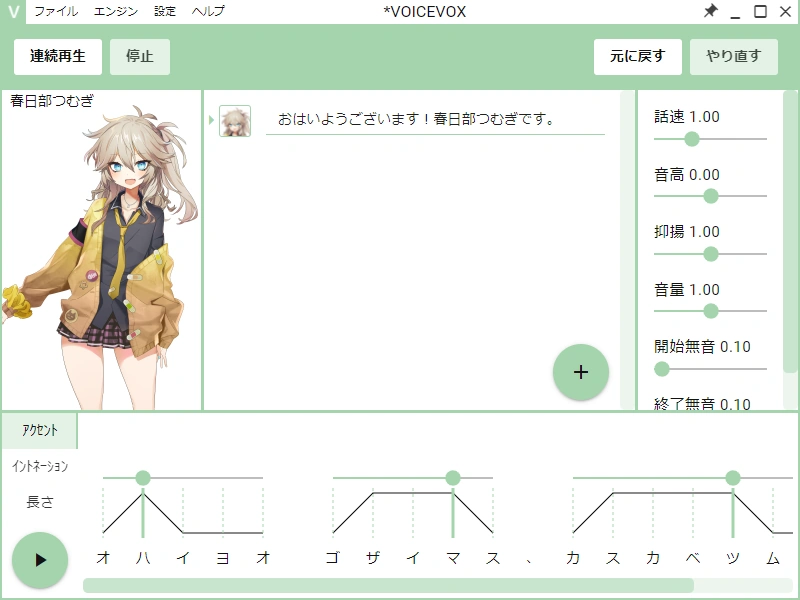
설치도 비교적 간단합니다. 공식 사이트(voicevox.hiroshiba.jp)에서 Windows, macOS, Linux용 빌드를 받아 실행하면 됩니다. 일본어 입력, 목소리 선택, 재생, WAV 내보내기까지의 흐름이 짧고 직관적이라 음성 합성 자체를 처음 만져보는 사람도 금방 적응할 수 있습니다. 인터넷에 연결되지 않은 상태에서도 모든 처리가 로컬에서 이루어지며, 입력한 텍스트가 외부로 전송되지 않는다는 점도 VoiceVox가 학습용과 업무용 양쪽에서 인기를 끄는 이유 가운데 하나입니다.
일본어 음성 합성기 역사
VoiceVox는 일본어 음성 합성이라는 오래된 흐름의 연장선 위에 있습니다. 일본에서는 2000년대 초반부터 AH-Software의 VOICEROID 같은 상용 음성 합성 제품이 나오기 시작했고, 2007년 전후부터는 창작과 더빙 현장에 꾸준히 사용되었습니다. VOICEROID는 대표적인 상용 TTS였지만 본질적으로는 사람이 녹음한 음성 라이브러리를 조합해 발화하는 방식이었고, 라이선스 비용도 제품과 목소리마다 따로 책정되어 자유로운 변형에는 한계가 있었습니다.
2020년에서 2021년 사이, Hiroshiba Kazuyuki는 딥러닝 기반의 오픈소스 일본어 TTS 엔진을 만들기 시작했고, 그 결과물이 VoiceVox로 공개되었습니다. 핵심 모델 학습에는 Hugging Face에 공개된 다양한 데이터셋과 PyTorch 생태계가 활용되었고, 학습된 음성 모델은 캐릭터 단위로 분리되어 캐릭터성과 음성 품질을 함께 관리하는 방식을 취했습니다. 엔진 자체는 MIT로 풀렸지만, 각 캐릭터 음성 모델의 라이선스는 별도로 운영되었기 때문에 저작권 측면에서 유연한 구조가 가능했습니다.
공개 이후 VoiceVox는 빠르게 커뮤니티가 커졌습니다. 개발자가 모델과 엔진을 개선하고, 일러스트레이터가 캐릭터를 그리고, 사용자가 음성을 활용한 콘텐츠를 만들면서 선순환이 자연스럽게 만들어졌습니다. 이후 AH-Software는 자사의 후속 라인업인 A.I.VOICE를 출시하면서 VoiceVox 엔진과의 연동을 점진적으로 제공했고, 상용과 오픈소스 사이의 거리가 좁혀지는 흐름이 이어졌습니다. 시간이 지나면서 ずんだもん을 활용한 2차 창작, 캐릭터 음성 패키지 추가, 일본어 외 발화 실험 등 다양한 확장이 프로젝트 자체에서 일어났습니다.
VoiceVox의 기술
VoiceVox는 신경망 기반의 엔드 투 엔드 TTS에 가깝지만, 실제 파이프라인은 여러 모듈로 나뉘어 있습니다. 입력 텍스트가 들어오면 먼저 일본어 전처리가 수행되고, 음소와 악센트, 휴지 정보가 추출됩니다. 그다음 음향 모델이 텍스트 특성을 멜 스펙트로그램으로 변환하고, 보코더(vocoder)가 다시 그 스펙트로그램을 실제 파형으로 바꿉니다. 결과적으로 우리가 듣는 음성이 만들어집니다.
음향 모델과 보코더
현재 공개된 정보와 커뮤니티 분석을 종합하면, VoiceVox 계열 모델은 VITS 기반 구조와 그 파생 모델에 가까운 음향 모델을 사용합니다. 일본어 운율을 자연스럽게 만드는 데 초점이 맞춰져 있고, 멜 스펙트로그램을 만드는 부분과 파형을 합성하는 부분을 분리해 품질을 점진적으로 끌어올려 왔습니다. 보코더 부분은 GPU가 있을 때 더 빠르게 동작하도록 최적화되어 있으며, GPU가 없는 환경에서는 CPU 모드로도 합성할 수 있습니다.
기화(기호) 모드와 API
VoiceVox의 큰 장점 가운데 하나는 일본어 입력을 기호 기반 표기로 다룬다는 점입니다. 같은 문장이라도 어느 위치에 휴지를 넣고, 어느 단어에 강세를 줄지에 따라 자연스러움이 크게 달라지기 때문입니다. 사용자는 GUI에서 직접 휴지 위치와 강세를 조정할 수 있고, API를 통해서도 같은 파라미터를 전달할 수 있습니다. 이를 통해 영상 더빙, 게임 내 대사, 학습 자료처럼 발화 스타일이 중요한 작업에서 미세한 조정이 가능합니다.
GPU 가속과 CPU 모드
CUDA를 지원하는 NVIDIA GPU가 있으면 음성 합성 속도가 크게 빨라지고, Apple Silicon 환경에서는 Metal Performance Shaders 기반의 가속이 동작합니다. GPU가 없는 노트북이나 저전력 PC에서도 CPU 모드로 동작하지만, 길이가 긴 텍스트를 한 번에 합성할 때는 시간이 더 걸릴 수 있습니다. 합성 품질 자체는 GPU/CPU 모드 사이에서 거의 차이가 나지 않도록 설계되어 있어, 개발용과 시험용으로 가볍게 돌려보는 일에도 잘 맞습니다.
개발자 통합
엔진은 HTTP API 형태로 노출되어 있고, 다른 애플리케이션에서도 쉽게 호출할 수 있습니다. 문서가 GitHub 저장소에 정리되어 있어 OBS 같은 스트리밍 도구, EleutherAI 이후 시기에 나온 다양한 로컬 LLM 인터페이스, 그리고 A.I.VOICE 같은 상용 음성 합성 도구와의 연동 사례가 이미 다수 공개되어 있습니다. 같은 엔진을 백엔드로 두고도 사용 목적에 따라 GUI, CLI, 임베드, 자동화 파이프라인 등 다양한 형태의 프런트엔드를 만들 수 있다는 점이 VoiceVox 생태계의 핵심 구조입니다.
사용 사례와 용도
VoiceVox는 단순한 음성 합성 도구가 아니라 일본어 콘텐츠 제작 도구의 한 축으로 자리 잡았습니다. 가장 대표적인 사용처부터 살펴보면, 우선 유튜브 영상입니다. 일본어 해설, 애니메이션 감상, 게임 리뷰, 시사 요약 같은 장르에서 VoiceVox 목소리가 내레이션으로 사용되며, 이 덕분에 제작자 한 명이 텍스트 스크립트만으로 일정한 톤의 음성 영상을 꾸준히 만들어낼 수 있게 되었습니다.
두 번째 영역은 VTuber 콘텐츠입니다. 가면을 쓰지 않고 VoiceVox 음성만으로 활동하는 중부(나메치)라고 불리는 방송 형태가 인기를 끌었고, 시청자 채팅에 음성으로 답하거나 게임을 진행하는 데 VoiceVox가 활용됩니다. 방송국형 콘텐츠뿐 아니라, 개인 방송과 단편 영상에서도 같은 목소리로 일관된 캐릭터를 유지할 수 있다는 장점이 큽니다.
그 밖에도 음성 합성이 실제로 쓰이는 자리는 꽤 다양합니다. 동인 게임 더빙, 팬 더빙 영상, 발음 연습용 학습 자료, 오디오북, 팟캐스트 자동 생성, Discord 음성 봇, 시각 장애를 위한 읽기 보조 도구, 사내 교육 자료의 음성 안내 등 한 번쯤 본 적이 있는 일본어 음성 콘텐츠 상당수가 VoiceVox의 영향을 받아 만들어집니다. 음성 합성을 도입한 뒤에는 보통 한 사람이 처리하던 대본 작업과 녹음 작업이 한 단계로 합쳐지고, 수정과 재녹음 비용이 크게 줄어드는 효과가 나타납니다.
제공 목소리와 라이선스
VoiceVox는 처음 설치할 때 몇 가지 기본 음성이 포함되어 있고, 이후 공식 사이트와 캐릭터 페이지에서 음성 라이브러리를 추가로 내려받을 수 있습니다. 유명한 캐릭터를 간단히 살펴보면 四国めたん(시코쿠 메탄)은 차분한 톤과 활기찬 톤을 함께 제공하는 표준 음성이고, ずんだ몬(즈ンダ몬)은 친근한 어조 덕분에 가장 널리 쓰이는 음성 가운데 하나입니다. 春日部つむぎ(가스카베 츠무기), 雨晴はう(아메하레 하우), 波音リツ(나미네 리츠), 玄野武宏(쿠로노 타케히로), 白上虎太郎(시라카미 코타로우), 青山龍星(아오야마 류세이) 등은 각각 다른 톤과 감정 표현을 가지고 있어 같은 대본이라도 분위기를 크게 바꿀 수 있습니다.
영어 음성으로는 Lucy 등 제한적인 화자가 제공되며, 일본어 외 언어의 품질은 아직 일본어에 비하면 다듬어질 부분이 남아 있습니다. 다국어 확장은 계속 시도되는 주제이지만, 현재로서는 일본어 합성 품질이 가장 안정적이라고 보는 편이 정확합니다.
라이선스 준비
라이선스는 두 단계로 이해하면 편합니다. VoiceVox 엔진 자체는 MIT 라이선스이기 때문에 상업용이든 비상업용이든 자유롭게 통합할 수 있습니다. 반면 각 캐릭터 음성 모델의 라이선스는 캐릭터마다 다르고, 같은 캐릭터라도 변주 음성(Normal, Sweet, Calm 등)에 따라 별도 조건이 붙는 경우가 있습니다. 유튜브, 동인 게임, 사내 교육 영상에서 사용하려면 각 음성 페이지의 이용 약관을 직접 확인하는 것이 안전합니다. 출처 표기가 필요한 경우도 있으므로, 제작 작업 초반에 라이선스 페이지부터 한 번 읽어 두는 편이 좋습니다.
상용 TTS와 결합
상용 음성 합성 도구와도 결합해서 쓸 수 있습니다. AH-Software의 A.I.VOICE는 자체 GUI를 제공하면서 동시에 VoiceVox 엔진과의 호환을 지원하므로, 한쪽 환경에서 만든 스크립트를 다른 쪽에서 그대로 활용하는 식의 작업이 가능합니다. 무료와 유료를 같이 다루는 사용자는 라이선스 비용과 음성 다양성, 워크플로우 편의성을 한꺼번에 따져 보게 되는데, VoiceVox는 그 비교의 기준선 역할을 종종 합니다.
VoiceVox와 일본어 TTS의 미래
일본어 음성 합성이라는 분야는 최근 몇 년 사이에 큰 폭으로 발전했습니다. VOICEROID, A.I.VOICE, VOICEPEAK 같은 상용 제품이 발화 품질과 안정성을 끌어올렸고, VoiceVox는 그 흐름을 무료로 열었다는 점에서 상징적입니다. 오픈소스 엔진은 무료라는 점만으로도 가치가 있지만, 실제로 더 큰 의미는 모델과 코드를 누구나 들여다볼 수 있고, 필요하면 직접 수정할 수 있다는 투명성에 있습니다.
다만 명시적인 한계도 있습니다. 첫째, 일본어 외 언어의 품질은 일본어만큼 안정적이지 않습니다. 둘째, 캐릭터 음성 모델의 라이선스가 통일되어 있지 않아 상용 콘텐츠에서는 매번 확인이 필요합니다. 셋째, 실시간 합성 지연이 완전히 0에 가깝지는 않기 때문에 라이브 방송처럼 즉각 반응이 필요한 환경에서는 워크플로우 설계가 필요합니다.
기능과 윤리적 문제
앞으로의 흐름을 가늠해 보면, 우선 실시간 합성 지연의 감소가 가장 직접적인 개선 포인트입니다. 저지연 합성은 라이브 방송, 음성 비서, 게임 내 실시간 대사에서 체감 품질을 크게 바꿉니다. 동시에 VALL-E, SoundStorm처럼 자기 음성 데이터만으로 새로운 음성을 합성하는 신경망 코덱 모델이 본격화되면서, VoiceVox 류 프로젝트도 자신의 음성으로 새로운 캐릭터를 학습시키는 방향으로 확장될 가능성이 높습니다.
음성 클로닝과 딥페이크 이슈는 피할 수 없는 주제입니다. 기술적으로는 자신의 목소리를 그대로 디지털화하는 것이 점점 쉬워지고 있지만, 동의 없는 사용, 유명인 사칭, 허위 정보 생성 같은 문제는 윤리적으로 계속 다뤄져야 합니다. VoiceVox처럼 음성 모델이 캐릭터 단위로 공개되는 경우, 얼굴과 성격이 함께 정의된다는 점에서 책임 소재가 비교적 분명하다는 장점이 있고, 향후 새로운 캐릭터를 추가할 때도 이 원칙을 유지하는 것이 중요합니다.
커뮤니티와 개발
마지막으로 커뮤니티 측면이 있습니다. GitHub 저장소, 공식 Discord, Twitter, Qiita와 Zenn의 기술 블로그 등을 중심으로 개발자, 사용자, 일러스트레이터가 계속해서 기능 개선, 음성 추가, 가이드 정리를 이어가고 있습니다. 음성 합성 자체는 기술이지만, 그 기술을 누가 어떤 캐릭터와 함께 만들 것인가는 문화적 선택에 가깝습니다. VoiceVox는 그 선택을 무료로, 그리고 사용자 참여로 열어 둔 프로젝트라고 할 수 있습니다.
일본어 음성 합성이라는 분야가 어디까지 갈지는 아직 두고 볼 일입니다. 다만 오픈소스 일본어 TTS의 기준선이 이미 만들어졌고, 그 위에 새로운 음성과 새로운 도구가 계속 쌓이고 있다는 점만은 분명합니다. 일본어 콘텐츠를 만드는 사람이든, 일본어 학습을 위해 자연스러운 음성을 듣고 싶은 사람이든, 한 번쯤 직접 들어 보면 VoiceVox가 왜 이렇게 널리 쓰이는지 감이 잡힐 것입니다.


커뮤니티
댓글
0개 댓글
이 언어로 공개된 댓글이 아직 없습니다.
댓글 보내기